灵魂绑定代币的实用性被夸大?聊一聊其面临的挑战与潜在机遇
灵魂绑定代币再次在加密圈引发热议。加密风投机构1confirmation合伙人近日在推特上表示,灵魂绑定代币(SBT,Soulbound Tokens)的作用被夸大,除了在技术上并无多大创新外,其作为身份或资格管理工具的实用性也有限。
自以太坊联合创始人Vitalik Buterin(V神)在共同撰写的论文中提出SBT以来,中外社区就对其有着广泛的关注和讨论,SBT也被寄予成为个人链上身份凭证的厚望,以打开Web3新世界的大门。
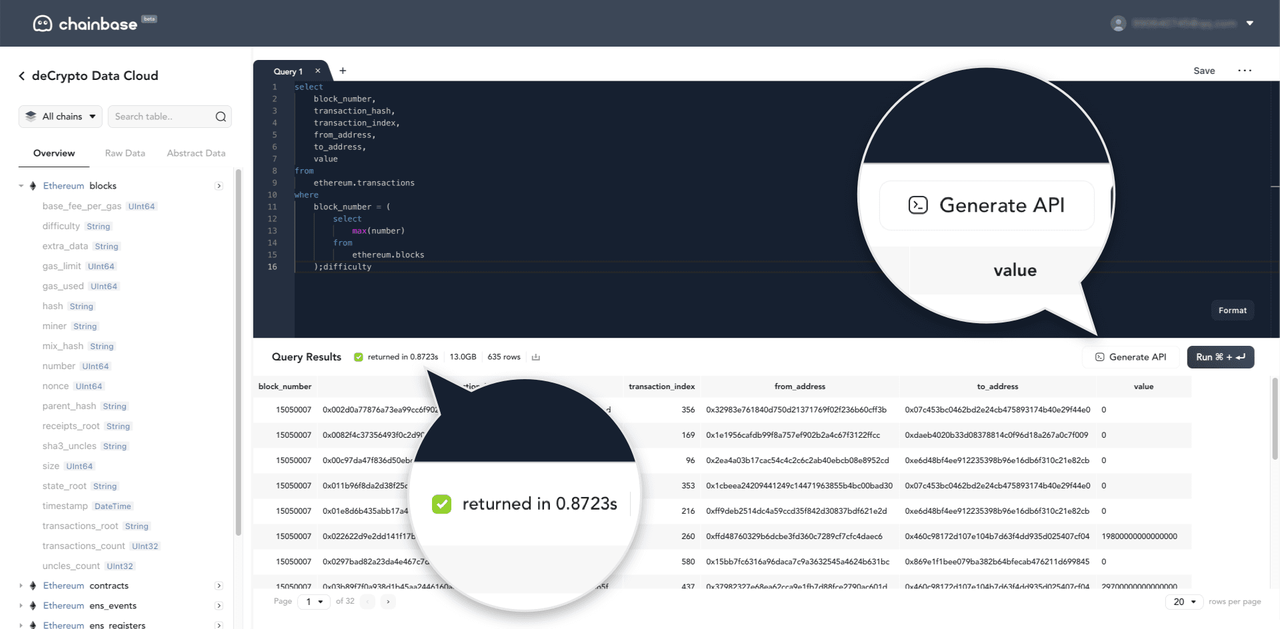
根据V神在论文中所介绍的,SBT拥有诸多潜在的应用场景,比如无质押贷款、社交恢复、灵魂空投、DAO 防御等,尽管SBT具有一定潜力,但由于该概念尚处于早期,还面临着不小挑战。目前关于的介绍较多,在此不再赘述。本文PANews将从Nifty Table的质疑出发,详细介绍SBT在实施中的挑战与解决方案,以及目前基于SBT所构建的具体产品用例。
挑战和解决方案
SBT的提出是为了给用户带来一个更加丰富的Web3世界,即将现实社会结构(如家庭、教堂、团队、公司等)带入Web3中,而不仅仅是金融系统(DeFi)。据PANews了解,“灵魂绑定”概念来源于多人在线角色扮演游戏“魔兽世界”,游戏中大多数强大的物品都是灵魂绑定的,灵魂绑定物品一旦被拾取,就不能转让或出售给其他玩家。
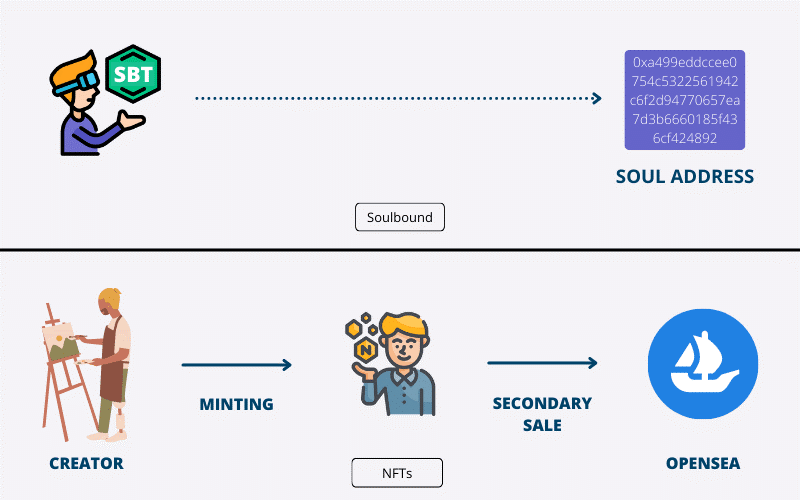
同理在Web3世界中,每个个人账户都是一个“灵魂”,可以拥有代表不同意义的SBT,比如代表学历证书、就业经历、技能培训历史等,同样一个组织的账户也可以是一个“灵魂”,比如以太坊基金会,可以为参加开发者大会的参会人员发放SBT,代表参与的凭证。所以SBT可被视为一种不可转让与交易的NFT。
不可转让性的潜在风险
虽然SBT旨在通过不可转让的形式,实现用户身份或资格的证明,但目前“不可转让性”会使用户面临一定风险。如Nifty Table所言,利用NFT作为用户链上和链下行为与属性的证明,是具有一定价值的,比如出勤证明(POAP)就是一个很好的用例。但SBT与钱包进行“不可转让”的绑定,是不合理的。用户往往会因为诸多原因,更换自己的钱包,比如为了安全起见,用户会将NFT等资产转移到多签钱包等,这是一个常见的需求。此外,因为SBT不可转让,一旦钱包被套,用户将失去这些“凭证”,反而落入黑客手中。
与现实世界我们丢失了个人身份证相比,SBT落入他人手中所造成的后果将会更加严重。比如黑客可以利用用户的SBT进入其专属的社交频道,散布一些谣言,或者利用SBT解锁其它功能,如获取相关隐私信息,造成用户信息泄露。此外,黑客还可能利用SBT进行链上信用借贷等活动。
除了上述的损失外,用户自身也丧失了链上身份凭证,由于有些活动或经历是不可能复制的,所以这部分凭证可能无法再次获取,比如用户无法重新参加Arbitrum奥德赛首周跨链桥活动以获得相应凭证等。
虽说SBT的不可转让性具有潜在风险,但如果像传统NFT一样可以转让的话,又可能失去“绑定”的意义,并引起虚假行骗等行为,比如某社交频道需要持有相应SBT才有资格进入,那么用户就可以通过转让SBT使多个钱包达到进入的标准。“不可转让性”的风险问题,或许还需依赖行业和技术的发展以解决。
过度公开问题
除了“不可转让性”的问题外,过多公共SBT可能会透露较多关于“灵魂”的信息,具有隐私泄露的隐患。由于区块链账本的公开性,任何链上的记录对所有人而言都是可见的,当一个“灵魂”拥有多个公共SBT时,比如毕业院校、工作经历、社交关系、社交活动、投票记录、技能证书等,其他人有可能将这些SBT串联起来以推测出“灵魂”背后的实际身份,最终导致个人信息泄露。
针对上述过度公开问题,现已有技术难度和功能性均不同的解决方案,其中最简单的就是链下存储数据,而链上只留数据的哈希值,用户可以自由选择何时披露完整的数据信息。对于链下存储数据的方式,用户可以选择自己的设备、受信任的云服务、去中心化网络(如星际文件系统IPFS)等。
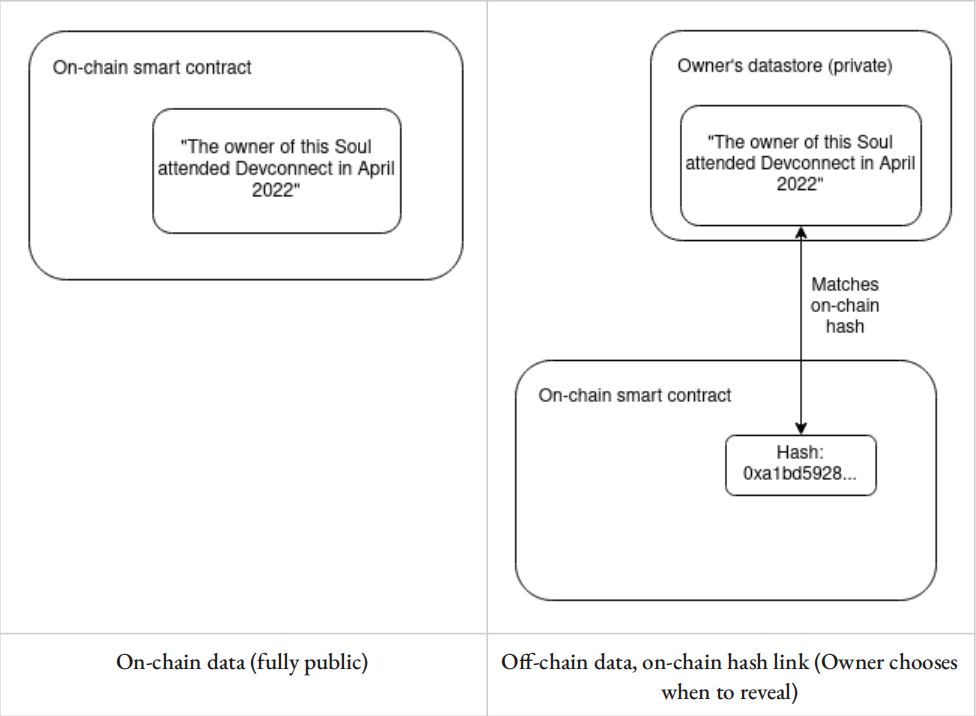
为了完全实现对各种类型隐私的保护,还需加密技术提供进一步的帮助,比如“零知识证明”技术。目前零知识证明往往用于资产转移的隐私保护,鉴于其允许证明任意陈述的同时不泄露陈述以外的任何信息,所以它也可以应用于SBT上,比如一个SBT可以证明你参与了Gitcoin 14轮捐赠,同时不会透露具体的捐赠金额、项目、时间等额外信息。
行骗问题
除了上述问题外,“灵魂”可能会通过私人或其他辅助渠道进行沟通交流以达到行骗的目的。与DAO的投票治理可以被贿赂相似,如曾经关于稳定币交易协议Curve的流动性之战,“灵魂”也可能会通过欺骗手段进入社区,以获得SBT许可的治理权或产权。比如,许多应用和协议依赖于可以代表会议出席权的SBT,那么就有可能出现利用这些SBT进行贿赂的情况,最终将生成一个虚假的社交图景,可以简单理解为没有参加相应活动但却通过贿赂获得了参与凭证。
针对该问题,目前已提出相应的解决方案,包括但不限于:
·SBT的生态可以从密集的社交渠道中开启,以通过强大的社会纽带和彼此的互动来证实链下的社区成员的身份;
·利用SBT生态的开放性和密码学可证明性,积极检测共谋模式并惩罚不可靠的恶意行为;
·利用零知识证明技术,遏止“灵魂”出售证明的行为;
·鼓励举报行为,使这种大规模勾结变得不稳定等;
·使用同行预测机制,即由与会者来证明彼此的出席,而不是由会议来证明与会者的出席;
·利用一些“灵魂”拥有的共同利益,建立衡量两者相关性的系数因子,从而确定他们的交集度。
Marry 3:链上“结婚”证明
虽说SBT概念还处于早期阶段,且面临种种挑战,但已经激起不少加密业内人士的兴趣,同时“拓荒者”也正在不断探索SBT的新玩法,构建基于SBT概念的相关应用。据PANews了解,近期新上线的“”项目,就是一款利用SBT来构建链上关系证明的应用。

Marry 3项目由致力于连接全球Web3建设者的NextDAO的两位社区成员创建,旨在通过SBT实现“爱”的链上证明。具体玩法就是,用户可以将一个地址与另一个地址“结婚”,即mint一对SBT的关系证明,双方各持一个。不过整个mint过程需要多签确认才会生效,所以只有地址双方互相确认才可以mint。由于Web3世界是基于账户而不是个人,所以用户通过Marry 3除了与爱人在链上建立关系,也可以与爱宠生成一对SBT。
与现实世界类似,Marry 3也仅支持用户生成一对“结婚”凭证的SBT,只有当解除关系后,才能与其他地址生成另一对SBT,当然,解除关系同样需要多签确认。如果遇到对方已经无法使用地址或协商的情况,用户可以向MarryDAO提交仲裁,之后MarryDAO将会进行强制解除。
据PANews了解,截至6月29日,Marry 3上已经“结婚”的couples有48对,目前mint的手续费为0.01ETH,随着参与用户的增加,mint的价格也会随之上涨,最高为0.05ETH。目前Marry 3仅上线“结婚”功能,未来将逐渐上线“离婚”、纪念日证明、与其它社交应用合作等更多功能。
通过Marry 3将现实的亲密关系搬到链上,我们看到了SBT除了论文所提到的无质押贷款、社交钱包恢复、优化空投机制等应用场景外,也还存在其它的想象空间和玩法,比如在GameFi中应用于等级、战绩、特殊技能等方面。
小结
Web3世界无疑是加密行业所憧憬的未来,在DeFi筑造了经济活动的底层基础后,如何拥有与现实世界一样的社会身份凭证,对于未来构建一个丰富多彩的Web3世界至关重要。灵魂捆绑代币SBT虽说距离像DeFi一样较为成熟还有些距离,但加密行业从不缺乏“拓荒者”,或许SBT也会像NFT、GameFi等一样,在“陌生”的背后也隐藏着一定的机会。