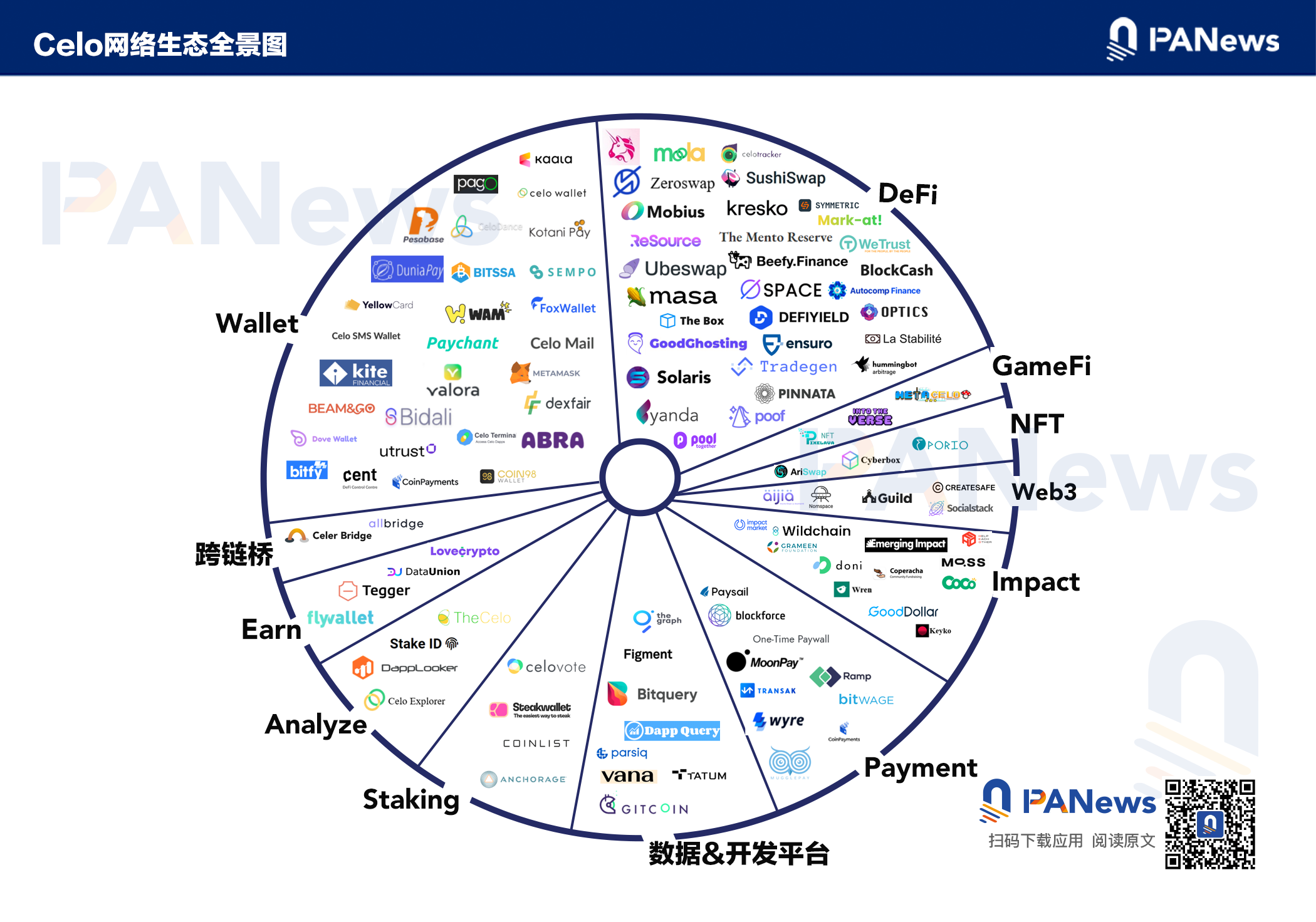
一览Celo网络生态全景,“ReFi Summer”带来了生态繁荣吗?
随着最大的DEX协议Uniswap V3正式部署至Celo网络,Celo也为自己的生态吸引到了影响力最大的项目。借助于Uniswap的深度、无许可性以及集中流动性架构,Celo将在其上构建与碳信用代币相关的流动性池,以提升碳市场的资本流动性,同时也为其他协议在Celo上整合碳信用打下基础,第一个流动性池将是Moss碳信用代币池CELO/MCO2。
与很多面向所有市场的Layer1的公链不同,Celo定位是一条主打去中心化移动支付的区块链网络,其主网于2020年4月正式上线,旨在让全球没有银行账户的用户也能够通过手机等移动设备享受DeFi产品所带来的便利性,所以非洲和诸多欠发达国家是其市场重点。除了采用PoS共识机制、兼容EVM、具有跨链互操作性外,其特点还包括以稳定币作为汇款、跨境支付等交易媒介、支持多种代币支付Gas费、将电话号码映射到钱包地址以简化转账操作等。2021年4月,欧洲最大的电信运营商德国电信公司宣布对Celo进行投资,此前的投资机构还包括a16z、Coinbase Ventures、Electric Capital、Jack Dorsey等。
除了推动去中心化金融的发展外,Celo还致力于为环保事业做出贡献,此次和Uniswap“结盟”也是为了共同推进ReFi(Regenerative Finance)的发展。顾名思义,ReFi指的是可再生金融,旨在通过Web3技术扭转气候变化,即利用区块链技术的透明机制,将现实中的自然资产引入链上,同时引入激励机制,对绿色发展作出贡献的行为进行奖励,以推动可持续性发展。据Celo基金会估计,ReFi将是一个万亿规模的经济市场,目前最常见的ReFi项目就是碳信用代币化类,比如Toucan、Flow Carbon和Moss等,Celo也与上述项目建立了合作关系,而碳信用代币的流动性问题是当下面临的挑战之一,此次Celo与Uniswap的合作也是为了提升该市场的资本效率。ReFi是一个全新叙事,PANews也对其进行了深度解读。
据PANews统计,目前 Celo生态产品已经初具规模,截至7月20日,其Dapp和协议约为120个,包括DeFi、GameFi、NFT、Web3、社会影响类、支付类、数据和开发平台、Staking、分析工具、跨链桥、钱包、Earn等,Celo生态的总TVL约为1.39亿美元。其中DeFi、钱包和社会影响类的项目权重较高,占比分别约为26%、24%和10%,以DeFi类为例,生态原生项目的占比将近一半,但目前原生项目的规模还较小,其中社会影响类的项目中有多个面向贫困人口的金融服务和扶贫协议明确的体现出了Celo生态的特点。
DeFi

于7月13日与Celo建立合作关系,为碳市场带来准入和流动性。
是一种多链兼容的去中心化交易聚合器协议,专注于降低交易成本。
是一个基于Celo网络的跨链稳定币交易DEX,专注于稳定币和计息代币间的低滑点交易。
是Celo网络上的去中心化交易所,旨在通过利用Celo的快速交易时间、区块气体限制和稳定币系统从所有 DeFi 中引入流动性。
是部署在Celo上的去中心化借贷协议,目前其TVL约为1200万美元。
是一款DeFi储蓄游戏,旨在通过游戏化的方式吸引用户存储资金,玩家需要先向储蓄池存入资金后才可以参与游戏。
是部署在Celo上的收益平台,支持用户单币质押(如CELO代币)和提供LP(如CELO/MOBI)赚取收益。
是一个支持无抵押贷款的借贷协议,此外还支持NFT(ERC 721)抵押贷款,用户在享受无抵押贷款服务前,需要先创建DeFi信用评分。
是一种去中心化的具有隐私保护的DeFi协议,包括借出、借入、转账等。
是一种跨链通信协议,与IBC和其他跨链通信协议类似,Optics在链之间创建通道,然后通过通道传递其消息。
是一个无损彩票平台,目前其TVL约为4000万美元。
是部署在Celo网络上的去中心化、自动复利的收益聚合器,用户选择金库并质押相应加密货币即可。
是部署在Celo网络上的去中心化合成资产平台,目前还处于测试网阶段。
是一个知名DeFi协议,目前其TVL约为7.2亿美元。
是一个多链收益聚合器,目前已支持BNB Chain、Avalanche、Polygon、Arbitrum、Optimism等16条区块链网络。
是最初部署在Evmos和zkSync上的跨链Web3多功能平台,其产品包括代币兑换、流动性挖矿、铸造和质押NFT、孵化和筹款平台等,未来将推出GameFi、Social Network等。
是一个跨链资产管理平台,除了查看资产余额、分布等外,Defiyield还为用户提供借贷服务,目前已集成以太坊、BNB Chain、Polygon、Arbitrum等27条区块链网络。
是基于Moola和Ubeswap的保证金交易,目前支持2倍、3倍的做多与做空交易。
是一个 HyFi(混合金融)协议,利用 CEX 基础设施连接CeFi和DeFi,旨在提高链下交易的透明度。
是一个专注于资产管理、算法交易、虚拟交易的去中心化交易平台,同时还提供针对不同流动性池的历史收益分析服务,以帮助用户决策。
致力于成为一家去中心化、获得完全许可的保险公司,将允许每个人根据他们对资源和时间的需求参与其流动资金池,这笔资金将支持保险产品,为流动性提供者创造收入来源。
是一个基于Mobius的DeFi协议,用户可以将支持的Mobiu LP锁定以换取协议的国库代币,然后利用国库代币铸造稳定币stabilUSD,该稳定币可用于Ubeswap挖矿等。
是一个移动版的非托管DeFi中心,降低用户访问不同DeFi协议的门槛,简化在不同DeFi协议进行交易的操作流程。
支持用户为任何目标筹集资金,比如集体礼物、捐赠、筹款等,此外,个人还可以将The Box 用作储蓄账户,他们可以设定一个目标并开始为该目标存钱。
是一个将Celo生态系统纳入跳蚤市场进行支付的项目,支持用户无需使用当地货币即可完成交易,简化了支付流程,同时还提供自动兑换功能,无需现有兑换流程,手续费成本更低。
是一个集成储蓄、借贷和保险的多功能平台,通过去中心化以消除对“受信任的第三方”的需求。
是一款开源软件,可帮助用户构建在任何加密货币交易所(中心化或去中心化)都可以运行的做市和套利机器人。
是一个部署在Celo和xDai网络上的去中心化交易所,旨通过简化设计以降低用户进入DeFi的门槛。
协议旨在让用户利用他们已有的资源和技能建立一个更加循环、自我维持的经济,而不依赖于他们现有的信贷或外部投资。
提供了一个平台,让社区可以在此平台上创造价值稳定的数字资产,这些数字资产旨在追踪现有现实世界资产的价值,如cUSD旨在追踪美元。
是一个跟踪和管理用户在Celo网络上投资组合的一站式平台,包括代币、LP、NFT等资产。
GameFi

是第一款建立在Celo网络上的 Play-To-Earn的区块链游戏,玩家可以成为怪物训练师,在此角色扮演游戏中体验自己的冒险经历。
是部署在Celo网络上的一款PRG链游,同时用户还有机会在游戏体验中与Ubeswap、Moola Market 和 NFT Marketplace等DeFi协议进行交互。
是GameFi世界的集合,其NFT PixelAva是一个可交易的身份证明,PixelAva持有者可以将他们的个人信息存储在他们的PixelAva中。
NFT

是部署在Celo网络上的一个NFT交易平台,目前售价最高的NFT为18800枚CELO,约1.9万美元。
是一个支持多类别的NFT交易市场,包括数字艺术品、徽章、游戏资产等,此外还支持用户自行创建NFT。
是首个集成ReFi的NFT交易市场,即除了传统的NFT交易外,用户还可以交易与碳补偿相关的NFT证书。
Web3

是经过修改的ENS分支,用户可以从任何受支持的链中保留.nom并将名称用于Web3社交媒体资料、钱包名称等。
是一个专注于音乐行业的服务平台,致力于帮助创作者创作、管理和发展他们的音乐业务。
致力于构建一个易于使用的社交代币平台,使任何人都能够在开放的区块链上对他们的社区进行代币化。
是一个专注于粉丝和粉丝体验的现代票务和市场平台,目前还在开发中。
致力于帮助社区在Discord等通信平台启用会员资格管理,包括代币、NFT、POAP等,即满足一定条件的成员才可加入社区。
是一个全新的Web3平台,支持用户在其中构建链上简历并发布人才代币,让其他用户可以轻松投资于自己的职业生涯。
Impact(社会影响层面)

是一个去中心化的扶贫协议,旨利用去中心化金融的包容性,使任何社区都能实施扶贫机制。
是一家为新兴市场打造包容性金融科技产品的金融服务技术公司,目前与与小农、非政府组织和社会企业合作,以打造一个更具金融包容性的世界。
是一款筹款应用程序,帮助用户发起一项筹款活动并接收筹款,应用使用cUSD结算。
是一家非营利组织,其使命是激励个人和组织保护濒临灭绝的物种及其栖息地。
是一家专注于抵消碳足迹的公益公司,旨在通过平衡使命和利润以实现可持续发展。
旨在借助于区块链技术简化碳足迹抵消过程,并保证所做一切的可追溯性和透明度。
是一个由社区驱动以解决贫困人口基本收入问题的协议,用户可以直接在手机上接收具有真实货币价值的加密货币。
是第一个基于稳定币的去中心化众筹平台,消除了筹款的地理和政治限制,目前HEO平台已经在BNB Chain、Celo、Aurora 和以太坊主网上线。
通过运营和治理框架帮助公司实施和自动化其数字生态系统,从而提高采用率并降低与用户隐私相关的监管和合规风险。
致力于通过提供数字平台来帮助发展中国家的人民为未来储蓄、投资他们的企业并改善他们的农场,以摆脱贫困环境。
定位于委内瑞拉市场,允许用户通过APP和网页从超市、药店和独立供应商购买产品,帮助委内瑞拉的亲人购物,以支持用户向委内瑞拉的家人和朋友提供经济支持。
是建立在Celo网络上的筹款应用,支持用户无国界且免费地筹款。
Payment

是一个简化加密货币支付方式的工具,用户在数分钟内即可完成支付方式的设定,目前支持的加密货币有BTC、ETH、USDT、BCH、LTC、EOS。
是媒体网站通过其内容获利的一种新方式,支持用户付费阅读单篇文章,已解决目前按月收取订阅费的弊端。
为用户提供了开发Web3产品的全套解决方案,用户通过其产品Cryptum可以标记资产、创建货币、创建和销售 NFT、在电子商务中集成加密结账等。
是一家数字资产基础设施开发商,为开发者提供简单高效、功能强大的API,是现实资产与加密资产之间的重要流通通道。
专注于全球企业对企业的发票业务,通过稳定币实现即时支付,致力于使开发票比以往任何时候都便宜、快捷以及安全。
致力于为用户构建一种快速、简单、安全与合规的加密货币买卖方式,目前已支持80多种加密资产。
聚合不同流动性来源和支付方式,支持Dapp用户直接从Dapp购买加密货币。
是一个开发者集成工具包,允许用户在任何应用程序、网站或网络插件中购买或出售加密货币。
利用全球支付网关,使每个人都可以轻松使用加密支付,目前已服务全球总计10万多人。
是BTC和其它加密货币薪资解决方案的提供商,为寻找工作的远程工作者创建解决方案并以最佳方式获得他们的工资。
数据&开发平台

是一个建立在以太坊上的去中心化索引协议,用于索引和查询区块链相关数据。
是最大的区块链基础设施和服务提供商之一,其DataHub平台让开发人员无需成为协议专家即可使用区块链的独特功能,从而加速新Web3应用程序的开发。
是一个可视化组件库,用于构建区块链数据的可视化界面。
是一个一站式解决方案,包括可视化仪表盘、直观的可视化SQL编辑器、用于高级分析的SQL等。
是一个Web3数据平台,有助于在区块链数据之上构建其它功能,如在相关活动发生时向Dapp的用户发送实时警报等。
是一个数据生态系统,用户可以重新调整他们的数据,数据科学家可以在以前孤立的数据集上训练机器学习模型。
是一个为开发者服务的平台,通过将复杂的区块链操作简化为单行代码,简化了整个 Web3开发过程。
是一个基于以太坊去中心化协作平台,除了让开发者在开源项目中通过赏金的方式进行协作之外,Gitcoin还提供公开平台,供项目向社区及以太坊基金会申请资助。
Staking

是一个简化用户参与Staking的移动端应用,包括ETH、SOL、AVAX、Celo等。
是一个帮助质押代币CELO的用户进行自动投票的应用程序,同时自动将选票分配给APY较高的组群以优化回报率。
是一个合规代币融资平台,由协议实验室Protocol Labs、AngelList共同建立,也提供部分代币的Staking服务。
是一个受全球监管的加密平台,为用户提供集成的数字资产金融服务和基础设施解决方案,其服务包括托管、质押、治理、融资等。
此外,中心化交易所(如Binance、Coinbase等)也会提供Staking服务。
Analyze(分析服务)

专注于Celo网络的数据统计,包括日交易量、地址数、验证节点信息等。
是Celo网络的区块浏览器,用户可查看区块信息、交易信息等。
统计了Celo网络的链上提案信息,用户可查看每个提案的相关内容。
通过解码区块链智能合约数据,使用户可将查询结果可视化为图表和图形。
Earn

是一款移动端应用,用户通过浏览广告并完成任务即可获得奖励。
旨解决数据垄断问题,将允许数据民主化,同时用户可分享参与创造的价值。
是一种数字解决方案,可收集和交叉检查数字广告的准确消费者信息,用户拥有对数据的控制权并在浏览相应内容网站时获得奖励。
是一个专为旅行者设计的具有集成预订功能和完全个性化的综合旅行预算平台,比如获取自定义储蓄计划、目的地洞察、廉价航班等。
跨链桥

是一个支持EVM、非EVM、Layer2之间转移代币资产的跨链桥,未来还将支持NFT,目前Allbridge已支持以太坊、BNB Chain、Solana等14条区块链网络。
是由Celer网络主导开发的跨链桥,支持代币和NFT资产的跨链转移,目前已集成以太坊、BNB Chain、Avalanche、Polygon等33条区块链网络。
Wallet

Celo网络集成的钱包包括Metamask、Valora、Kaala、Coin98、FoxWallet、Utrust等29个钱包,包括网页端和移动端。