熊市指南:如何应对变幻莫测的加密世界?
作者:OP Research
先讲一个《三体》里的寓言故事:
一个农场里有一群火鸡,农场主每天中午十一点来给它们喂食。火鸡中的一名科学家观察这个现象,一直观察了近一年都没有例外,于是它也发现了自己宇宙中的伟大定律:“每天上午十一点,就有食物降临。”它在感恩节早晨向火鸡们公布了这个定律,但这天上午十一点食物没有降临,农场主进来把它们都捉去杀了。
在投资领域,人们都渴望观察到真理规律,企图做火鸡中的科学家,并利用所掌握的真理规律去预测市场,指导投资,所向披靡。然而,市场是否真的可以被预测,或者说是否有一劳永逸的规律可循?我们尝试从不同维度对比加密数字货币周期,看看不同周期之间的变化和不同,探索是否真的可以秉持经验主义的思想对待加密投资市场。
1. 宏观经济周期
宏观经济周期因素主要包括经济发展阶段和发展水平、财政和货币政策、CPI指数、PMI指数、黑天鹅事件等。其中各国的财政和货币政策被投资者看作市场走向的风向标,往往直接作用于资本市场;黑天鹅事件则形成市场的阿尔法因子,是投资者预期外的重大影响因素,对风险资产价格的冲击往往较大。
纵观加密市场,从2008年比特币产生至今,历经14年时间,其牛熊转换与全球财政和货币政策密切相关。例如2017年的加密市场牛市,源自2015年美联储原计划2016年加息4次,但实际加息步伐放缓,2016年仅实行了一轮加息,加之特朗普上台后推出的减税计划,随后2017年美股、比特币等风险资产价格持续上涨。2021年加密资产的牛市也显然得益于全球央行放水,而与以往降息放水不同是,社会生活和经济发展环境遇到了从未有过的情况。2020年爆发新冠疫情,居家隔离、居家办公、公共场所封闭、城市封锁、航线暂停已成为各国抗击疫情的常规手段,相比2008年金融危机,疫情对实体经济的冲击更为严重,不仅国际间贸易往来受阻,还对人们日常生活、消费也带来了严重影响,各国都降低了对经济增长的预期,失业激增、消费不振、经济衰退随之而来,全球悲观预期大幅上升。在新冠疫情这一黑天鹅事件影响下,各国罕见地出现了步调一致,不仅共同抗击疫情,同时为提振经济,防止经济衰退也都出台了前所未有的积极性财政和国币政策,为资本市场注入大量流动性。
以备受关注的美联储为例,新冠疫情中美联储从政策制定到执行的时间链条明显缩短,政策力度及工具创新方面均大幅超过金融危机时期。短短三个月内,美联储的资产购买规模已接近金融危机后四轮量化宽松政策的总规模,同时美联储通过SPV(特殊目的公司)买入企业债券和商业票据,在实现精准救助的同时快速拉低了市场信用利差,稳定了市场波动。
具体来说,为稳定市场,美联储2020年3月上半月两次紧急降息50和100个基点,联邦基金利率降至0.25%的低点,并宣布采取不设上限的量化宽松措施,3月下半月先后推出15项货币政策工具,向市场注入流动性,并直接为实体企业提供信贷支持。各国央行也纷纷加入降息放水的行列,史诗级的流动性带动了比特币等风险资产的超级大牛市。
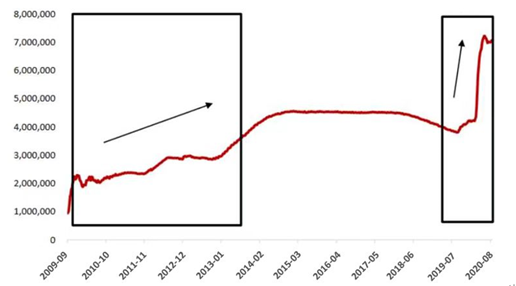
图1.1 2008-2020年美联储资产负债表变化(百万美元)
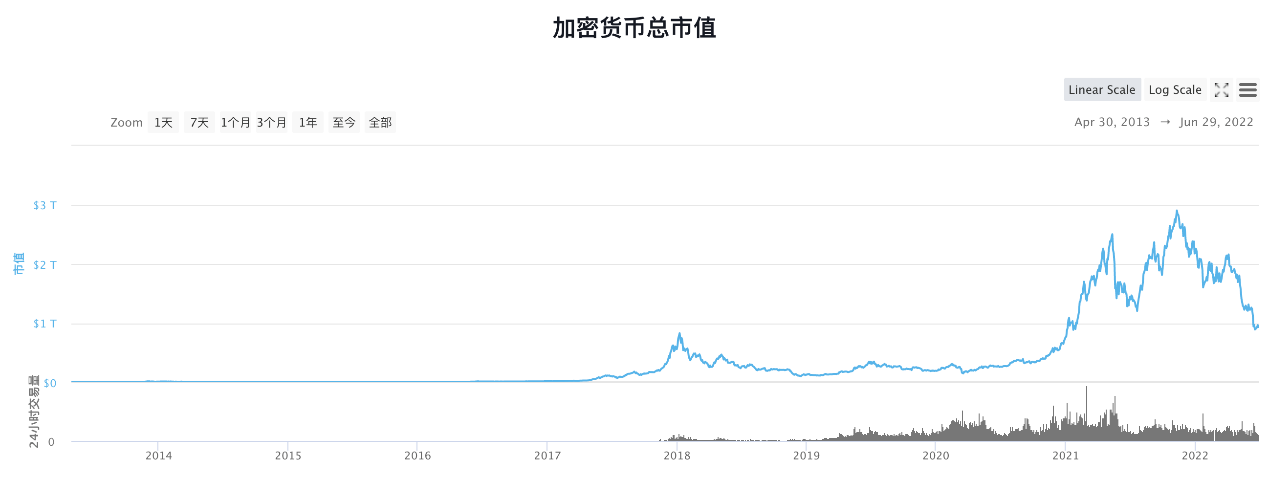
图1.2 2016-2022年加密货币总市值变化(美元)
Source:https://coinmarketcap.com/zh/charts/
虽然每轮牛市都离不开宽松的财政和货币政策,以及充足的流动性支持和宽松的市场环境,但是每轮周期各国央行执行各项政策的背景,政策执行的动机,经济大环境等均不一样,因此政策制定和执行的具体细节(如量化宽松规模,持续时间,利率水平)也会有所不同,由此对加密市场的影响也不能一概而论。加之近年来黑天鹅事件频发,也会对各项经济政策产生影响。因此,宏观基本面的分析要实事求是,不能单纯根据经验笼统下结论,需要通过细致入微的观察再对市场后续发展下判断。
2. 传统机构入场,更多的长期持有者
与2017年的牛市不同,2018年尝试通过BTC ETF,但是失败了。2021年开始的这波牛市显然是受到了传统机构入场的推动。这些机构,如摩根大通、渣打银行、花旗集团、德意志银行、星展银行集团、富达证券等,资金体量大,决策果断,且几乎都是长期持有,使得BTC的涨幅巨大且持续。当然,还有各种知名企业,在各大传统机构的背书之下,也参与了进来,将比特币作为配置资产。其中最为知名的就是Elon Musk的特斯拉了。马斯克曾以两条Twitter分别造成了BTC单日近20%的涨幅和跌幅,被大家冠以了币圈“喊单王”的称号。除此之外,BTC ETF和灰度基金则是这轮牛市最大的助力。各类BTC 、ETH的ETF(图2.1)给予了传统金融市场资金参与加密市场的机会,美国最大的BTC ETF——BITO的通过,为加密市场带来了数十亿美元的增量资金。而灰度基金作为美国最大的加密货币信托与合规业务标杆,其真正打开了传统资金入场的通道,为BTC带来了数百亿的买盘(图2.2)。由于客户购买灰度的GBTC后有6个月的锁定期,且即使过了锁定期,客户还是不能赎回,只能通过场外的二级市场退出,这使得GBTC的购买者大多都是长期持有者。甚至萨尔瓦多还把比特币定义为法定货币,先后买入了1.5亿美元的BTC。有了众多机构和企业甚至国家的加入,散户们也就有了进一步参与的信心。由此可见,这一轮牛市几乎是各大投资机构与新兴企业和寻求改变的主权国家联手推动的。
提及传统机构,那就不能不提加密货币的一级投资基金,随着整个市场资金量的暴涨,这些VC的资金规模也远比上一轮牛市要大,因此在这轮牛市中他们能做的事情也就很多,而更大的市场也给了他们更大的空间。例如,与上一轮牛市单纯投资Token不同,由于VC们有了更多的资源和更大的影响力,他们还会下场喊单和孵化投资的项目,同时整个融资周期也得益于这次长牛而被拉长。最明显的现象就是,这次山寨币们不仅获得了远超BTC和ETH的涨幅,还逐渐走出了独立行情,导致BTC市场占有率一度下降到40%以下。以A16Z为例,他们在各个板块寻找有潜力的项目,而一旦确定目标就不仅仅是为其提供资金,还会通过自己的影响力在各个媒体平台开始为其造势。Sky Mavis 和 Yuga Labs就是在A16Z资源下成长起来的典型案例,Axie Infinity曾经作为GameFi绝对的龙头,占据着GameFi板块大部分市值,尽管StepN的出现改变了这一局面;而Yuga Labs则更有说服力,就算是市场低迷的现在,BAYC仍旧拥有7.1%的NFT市场市占率,如果把Otherdeed与Crypto Punks和Meebits囊括进来,那就是约23%的市占率。一级投资基金在这轮牛市的影响也就不言而喻了。
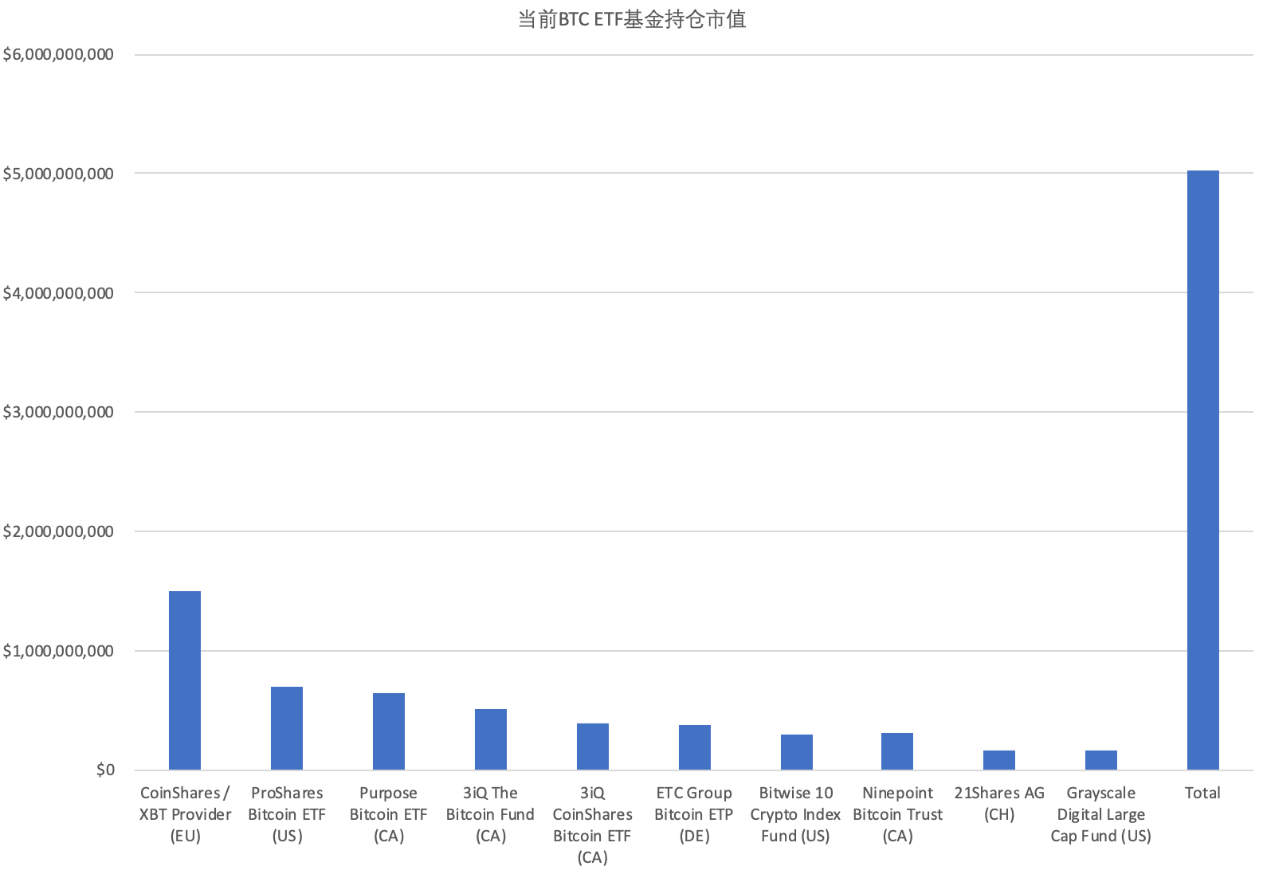
图2.1 部分BTC ETF基金BTC持仓市值
Source:https://www.coinglass.com/zh/BitcoinTreasuries
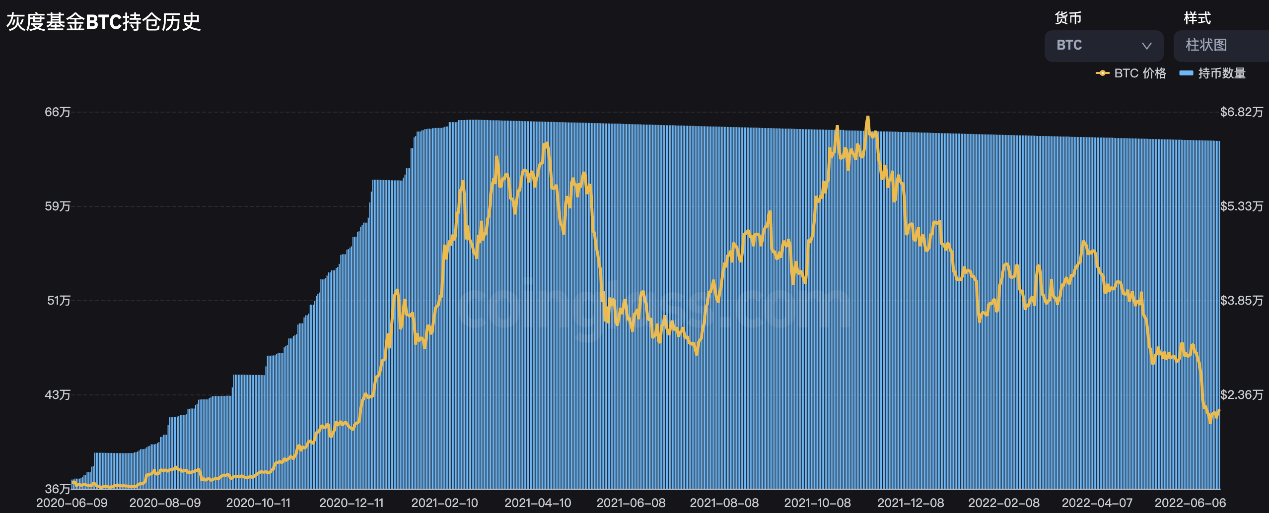
图2.2 灰度基金BTC持仓历史与BTC价格变化
Source: https://www.coinglass.com/zh/Grayscale
3. 叙事的变化、泡沫的来源
叙事的变化往往是牛市的强大推动力之一:在比特币冲破中心化的国家和组织的外汇管制后,以太坊的诞生也为加密行业的ICO热潮打下了基础。ICO市场的出现,本质上是对现有的证券市场构架与制度的冲击和颠覆,这也在当时直接或间接导致了2017年加密行业波澜壮阔的大牛市。不同于2017年的牛市,去中心化金融(DeFi)概念横空出世,成为了2020-2021这一波大牛市最初的发动机(图3.1链上TVL),因为DeFi为资金加杠杆提供了一个新的方式——链上借贷。这使得用户,特别是传统机构,在获得融资之后可以在链上进一步加杠杆,这也被3AC的爆仓事件证实。而在DeFi之后的GameFi也不过就是DeFi的换壳模式,其本质还是加上了游戏属性的DeFi。但不同的是,GameFi的兴起,伴随着NFT的火热,Crypto Punks、NBA Top Shot、BAYC等NFT系列一步步把NFT推向顶点,并迅速火爆全网,完成了NFT的出圈。NFT也就此从GameFiI手中拿过了接力棒成为资本市场最炙手可热的概念和全新的融资方式。NFT的募资是独立于传统私募和IEO/IDO的,其关键在于NFT自身属性的特殊性(详情可见我们的文章:“NFT,募资形式的范式转移”)。
高杠杆和叙事是推高加密资产市值的泡沫制造机,同时也是加速其下跌的催化剂:自从DeFi爆火以来,使用杠杆已经成了圈内资金的常态,例如最近的加密借贷平台 Celsius暴雷事件,因为用户在市场恐慌情绪下大规模挤兑存款,流动性严重不足的问题凸显,更深层次原因在于项目运营机制、风控策略长期存在严重问题,导致本次暴雷。又如3AC的爆仓事件,3AC在融资的基础上又去链上加杠杆,同时还不够清楚自己链上杠杆倍数和清算点,于是在连续经历UST、stETH脱锚等重大事故之后,被用户们围观爆仓。随着加密行业越来越多的CeFi/DeFi项目挤兑或者暴雷,行业过去两年高速增长所掩盖的问题在熊市中终于爆发。此外,众多昂贵的NFT和NFT发行中一次次的Gas War在推高NFT板块市值的同时,吸收和销毁不计其数的ETH,这使得泡沫增长的同时还让风险提升了。因为虽然一众项目的市值增长了,但是市场里的真心白银在减少,所以一旦出现退潮,泡沫开始消退,那么必然会出现如同DeFi挤兑一样的螺旋下跌式崩盘。特别是在NFT之后,虽然大家努力在Web3.0概念和DAO模式中寻找机会,但是它们并没用从DeFi和NFT概念中脱离,于是随着叙事的枯竭,行情的下跌可以说是“指日可待”。
因此我们需要重新审视一下这一轮牛市泡沫的来源和构成,而不是简单地以经验主义去判断。这一轮牛市中,DeFi和NFT以及众多基础设施持续发展,由于切实提供了技术进步和解决了一系列问题,从而为Crypto行业提供了实质性的价值。在这个基础上,资本利用新旧各种融资手段和一环套一环的故事吹出了巨量的泡沫。而传统机构的进场和Crypto连续出圈也为这轮牛市带来了足够的增量资金和增量用户,为泡沫提供了增长空间和膨胀速率。另一个需要重视的点是Crypto项目的估值方式,与ICO时代不同,现在的项目估值更有迹可循,项目基本面、官网质量、经济模型、代币分配、项目方经验、机构背书等等都被考虑了进去;而与传统互联网企业相比,Crypto项目又不完全依靠流量本身来定价,同时由于代码的特性和项目的开放性与可迭代能力,Crypto项目可以被视为近乎是永久存在的“企业”。所以这轮牛市的泡沫中还有一个“相对可靠的时间加成”。在高基数和众多加成因子的催动下,Crypto总市值从上一轮牛市的顶点7,000亿美元涨到了这一轮的30,000亿,而BTC也到达了69,000美元的最高价,其市值一度超越特斯拉位居世界第六(图3.2)。但由于盈亏同源,一旦有一个因子反转,下跌趋势形成,其市值下降速度也是极其恐惧的。这也就解释了为什么这轮牛市的泡沫会膨胀的如此之大之快,又在大家对BTC去往100,000美元的预期下,破灭得这么出乎意料。
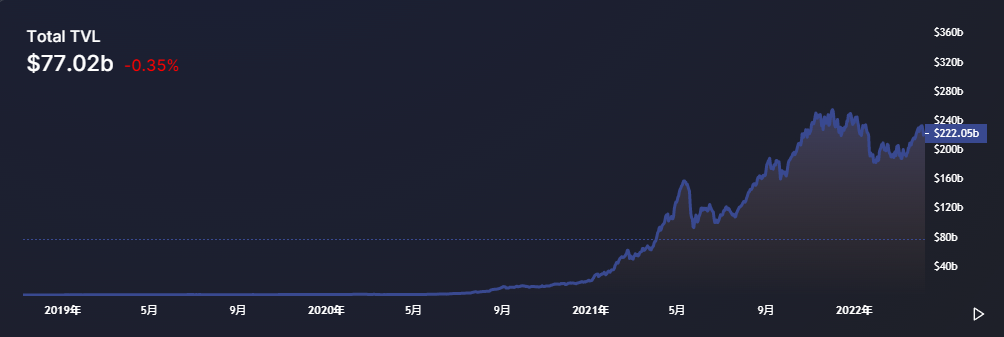
图3.1 Total TVL(all chains)
Source: https://defillama.com
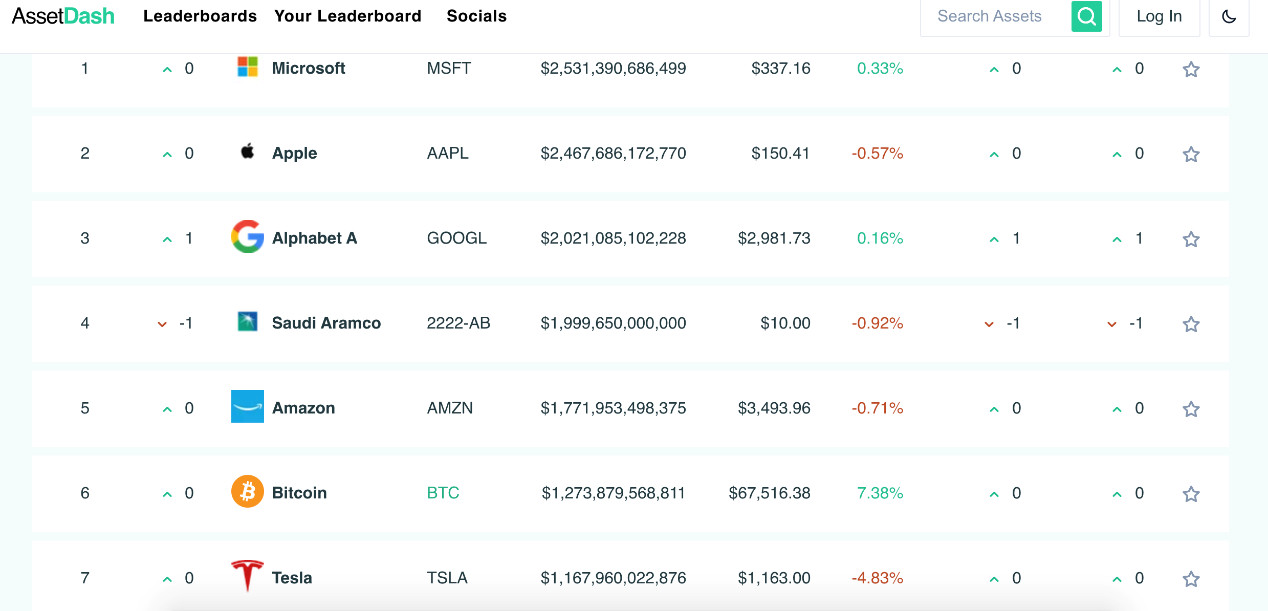
图3.2 2021年资产市值排名
Source:https://images.bitpush.news/cn/20211109/163641542751445079.png
4. 经验主义陷阱
在本文开头,刘慈欣小说《三体》里所描绘的火鸡科学家的故事被称为“农场主假说”。这个假说来源于哲学家休谟对因果关系的看法,休谟颠覆了因果关系的客观必然性,认为因果联系往往有时只不过是:两种事物恒常会合+主观的心理联想。而在加密行业的14年的历史里,我们也许自己就是农场里的火鸡:“四年一次的牛熊轮回”,“每逢产量减半迎来大牛市”,然而在这一轮周期里,越来越多的经验主义规律被打破:planB推崇的S2F模型(高库存流量比模型S2F是指将储备中的资产总数,除以每年产出的资产总额所得出的模型,主要用于凸显稀缺性及市场价格之间的关系,主要用于黄金和白银等流行金属。由 PlanB 于 2019 年提出,他认为这可以排除掉其中因偶然性事件引发的价格波动。从 S2F 模型推论,比特币价值将会在 2024 年达到惊人的 288,000 美元。)已经被证明失真,就连以太坊创始人Vitalik Buterin也在推特上批评比特币S2F模型(Stock-to-flow)给人带来一种错误的确定感,认为“预定的数字会给人增加有害的感觉,盲从者应该受到嘲笑”。无独有偶,在最近的一轮下跌中,比特币最近已悄然跌破上轮牛市顶点,打破了关于每一波熊市底都比上一轮牛市顶高的历史规律。
而当我们回顾过去两轮牛熊行情的时候,我们也会发现,2017年牛市的明显标志在于ETH带领的ICO,而2020年起的牛市来自于DeFi的爆发和全球范围的降息放水,这两轮牛市都伴随着着叙事的革命性创新和经济环境的剧变,那么有没有一种可能,过去两轮(因为2013年牛市时候市场体量较小所以这里不予对比)牛市的来临,其实只是因为叙事的进步和技术的革新,才形成了四年牛熊轮回规律?换言之,在样本量如此小的情况下,也许过去的每一轮牛熊和产量减半等因素并无关系,只是偶然而已。并且有没有可能,随着行业体量的增加,叙事的枯竭,周期和规律性的经验大多数将被打破,甚至进入过去没有经历过的长时间寒冬?我们是否迎来的是农场主假说里的感恩节?这些问题是值得深思的。
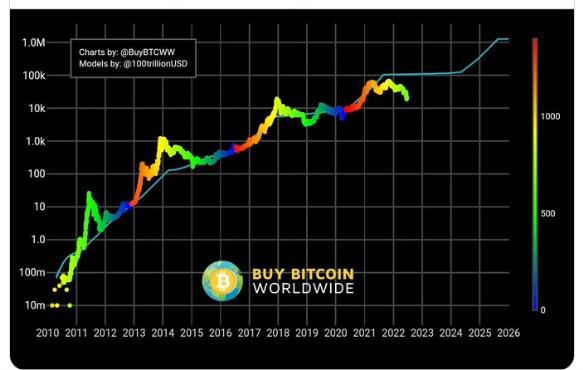
图4.1 S2F模型
Source: https://twitter.com/VitalikButerin/status/1539167095312850944
5. 反思和原则
加密市场天然带有金融属性,不断寻找新叙事是吸引资金和人才持续入场的重要方式,而只有当资金和人才源源不断地进入这个市场,新的叙事才有得以实现的基础。不可否认的是,在这一过程中,资金的大量涌入,各个项目团队的营销炒作,用户们FOMO情绪的助推,会使加密资产形成巨大的泡沫。虽然泡沫意味着远超自身价值的不良增长,但其也是点燃行业热情的火花,推动着行业的发展。上一轮周期中,只要有白皮书,有几人组成的团队,讲一个还算过得去的故事就可以在加密时长畅行,而这轮周期,相比上一轮有更多的落地应用出现,商业模式也比之前更成熟,基本面也更好,因此这轮牛市的泡沫并不完全是“无源之水”。不过,作为加密市场的投资者要尽可能保持绝对的理性,我们要始终保持怀疑态度,在拥抱泡沫的同时警惕泡沫,在泡沫中获取收益的同时控制风险——这才是最重要的。
同时,作为“理性人”还要避免陷入经验主义的陷阱。加密资产从产生至今也不过只有14年的时间,和其他资产相比历史很短,因此在这一过程中观察到的“规律”并不一定是真正的“真理”,可能是多种因素造就的巧合,或者还需要更长的时间验证去验证观察到的现象。过去不代表未来,规律不代表真理,谁也不知道明天和意外哪个先来,所以坚持技术发展为基础,坚持价值投资理念,才是行业发展的根本之道,也是投资的核心要义。
虽然单纯片面的经验主义不可取,但我们依然可以从历史中反思。目前市场处于熊市,我们可以通过总结并学习这些原则,待牛市到来之际,便可更加从容地应对。这些结论包括:
(1)永远要敬畏市场,因为黑天鹅事件不可预测,不要陷入经验主义陷阱;
(2)拥抱并警惕泡沫,泡沫是点燃市场的火花,在泡沫中可以获取收益,但也要对泡沫保持质疑;
(3)行业发展的核心是不断的创新,实现底层技术进步,最终还是要回归到价值投资;
(4)技术和宏观经济有其发展的规律和周期,与趋势为伍,不断的提高生产力才是基础;
(5)市场基本面在变好,熊市是检验应用和项目的试金石,因此保持乐观,才能赢得未来。